Calculating Probability with Mean and Deviation
By Kathleen Cantor, 30 Jan 2021
Calculating probability with mean and deviation depends on the type of distribution you'll base your calculations on. Here, we'll be dealing with typically distributed data.
If you have data with a mean μ and standard deviation σ, you can create models of this data using typical distribution. We can find the probability within this data based on that mean and standard deviation by standardizing the normal distribution.
The equation for the probability of a function or an event looks something like this (x - μ)/ σ where σ is the deviation and μ is the mean. Using the standard or z-score, we can use concepts of integration to have the function below.
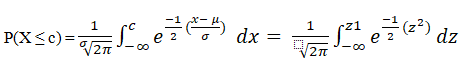
This might appear strange at first, but what it means is that anyone can find probabilities for any given normal distribution as long as they have the mean and the standard deviation without having to do any integration. As long as you have the standardized table with a standardized normal curve with a standard deviation (unity) and a single mean, you can calculate probability using the z-score. It is this same table that we will use to calculate probabilities in the examples below.

Using Standard Normal Distribution Tables
You can download this Standard Normal Distribution Table from the University of Arizona as a pdf or excel file. Look closely at the table; you will see that it contains values from negative infinity to x. X values are from 0 to 3, and in very rare cases, 4 bringing the probability daringly close to unity or one.
This means that P(X ≤ x) =
Calculating P(x) may appear straightforward, but what if you want to calculate for a range of numbers, say p(X > x)? This is outside of the values on the table but P(X > x) = 1 – P(X ≤ x). In this case, we'll look for the value of P(X ≤ x) and subtract from one.
Examples
1. What is the probability that 5 is greater than x in a normally distributed data given that the mean is 6, and the standard deviation is 0.7.
Solution
P(X < 5) the first step is to find the z- score. We find that using the formula above.
z = (x – μ (mean)) / σ (standard deviation) this means that
For P(X < 5), z = (5 - 6)/0.7
-1/7 = - 1.42857 which is rounded up to – 1.43
Now in the table, we will look for the value of -1.4 under 3
= 0.07636
The normal return for the z-score is usually less than, and because the function is asking for the probability of x being less than 5, this will be our final answer.
2. What is the probability that x is greater than 4.5 in a normally distributed data given that the mean is 6, and the standard deviation is 0.7.
Solution
P(X > 4.5) => the first step is to find the z- score. We find that using the formula below
z = (x – μ (mean)) / σ (standard deviation) this means that
For P(X > 4.5), z = (4.5 - 6)/0.7
-1.5/0.7 = - 2.14285 which is rounded up to – 2.14
Now in the table, we will look for the value of -2.1 under 4
= 0.01618
The normalization table returns for the z-score is usually less than, but the function is asking for the probability of x being greater than 4.5; this means that the value we got is for x less than 4.5 and not greater than 4.5. To get the probability for x greater than 4.5, we will have to subtract the answer from unity.
=> 1 - 0.01618 = 0.9838
3. Find the probability that x is greater than 3.8 but less than 4.7 in a normally distributed data given that the mean is 4 and the standard deviation is 0.5.
Solution
This problem is a bit different from the rest. Here we are asked to find the probability for two values when x is greater than 3.8 and less than 4.7. This means it falls between 3.9 and 4.6.
We can express this as P (3.8 < x <4.7).
Here we will be finding the z-score for P (x > 3.8) and P (x < 4.7). We find that using the formula below
z = (x – μ (mean)) / σ (standard deviation) this means that
for P (X > 3.8), z = (3.8 - 4)/0.5
-0.2/0.5 = - 0.400
Now in the table, we will look for the value of -0.4 under 0
= 0.34458
For P (X < 4.7), z = (4.7 - 4)/0.5
0.7/0.5 = 1.40
Now in the table, we will look for the value of 1.4 under 0
= 0.91924
We are going to subtract the upper limit by the lower limit
0.91924 - 0.34458 = 0.57466
The probability that x is greater than 3.8 but less than 4.7 is 0.57466
4. Find the probability that x is less than 6 but greater than 4 in a normally distributed data given that the mean is 5 and the standard deviation is 0.6.
Solution
We are looking for the probability that x ranges from 4.1 to 5.9
We can express this as P (4 < x < 6).
Here we will be finding the z-score for P (x > 4) and P (x < 6). We find that using the formula below
z = (x – μ (mean)) / σ (standard deviation) this means that
For P (X > 4), z = (4 - 5)/0.6
-1/0.6 = - 1.67
Now in the table, we will look for the value of -1.6 under 7
= 0.04746
For P (X < 6), z = (6 - 5)/0.6
1/0.6 = 1.67
Now in the table, we will look for the value of 1.6 under 7
= 0.95254
We are going to subtract the upper limit by the lower limit
0.95254 - 0.04746= 0.90508
The probability that x is less than 6 but greater than 4 are 0.90508
Conclusion
In a normally distributed data set, you can find the probability of a particular event as long as you have the mean and standard deviation. With these, you can calculate the z-score using the formula z = (x – μ (mean)) / σ (standard deviation). With this score, you can check up the Standard Normal Distribution Tables for the probability of that z-score occurring.
No matter the value of the mean and the standard deviation, the probability of x being equal to any number is automatically zero. There is an emphasis on a normally distributed data set because if your data isn't distributed normally, you may have to consider different factors like kurtosis.
See the 5 Comments below.
20 Mar 2021 at 10:45 am [Comment permalink]
Great presentation however I don't understand the tables you're talking about and it wasn't displayed in this page.
Please is there a place I can be referred to see the table or shown how to create the table with the values myself.
Thank you and truly appreciate your kind efforts.
22 Mar 2021 at 11:31 pm [Comment permalink]
Hi Peter, great question! There's a link to the table under the "Using Standard Normal Distribution Tables" section. I'm pasting the link here as well so you can see it: https://www.math.arizona.edu/~rsims/ma464/standardnormaltable.pdf
27 Apr 2021 at 11:49 pm [Comment permalink]
Do you guys have an example for a problem that is not normally distributed?
4 Sep 2021 at 9:15 pm [Comment permalink]
Hello Kathleen,
Thank you for the article.
I am having trouble finding a single value, given mean and deviation. In my case, I have (n=1000) cookies, the mu=971g (average weight), sigma=15.2g (standard deviation), and I need to find the weight of a single cookie, including it's probability distribution. If I use the above formula for z, then I get: 1.91, and following the table I find the value 0.97-ish. But I am lost, how I can connect the answer to my question. My question is: what is the weight of a single cookie, and what is it's probability distribution?
Hope you can help.
Thanks in advance.
8 Sep 2021 at 5:07 am [Comment permalink]
Hi Raja,
I'd recommend posting this question in the IntMath Forum where others are working through problems and can assist you.
Thanks!