Zipf Distributions, log-log graphs and Site Statistics
By Murray Bourne, 30 Jul 2007
An article by Jakob Nielsen, Zipf Distribution of Website Popularity inspired me to do some further reading and analysis of my own sites.
The basic idea of Zipf Distributions is that many phenomena follow a distribution where the second most common event occurs about half as often as the most common event. The 3rd ranked event occurs about 1/3 as often as the most common event.
This pattern is observed in word usage, wealth distribution, company size and artificial intelligence.
When it comes to word usage, the most common words "the" (7% of all words used), "of" (3.6% of all words used), "and" (2.9%), & "to" (2.6%) follow the pattern pretty well. But more remarkably, the pattern is very consistent for thousands of English words.
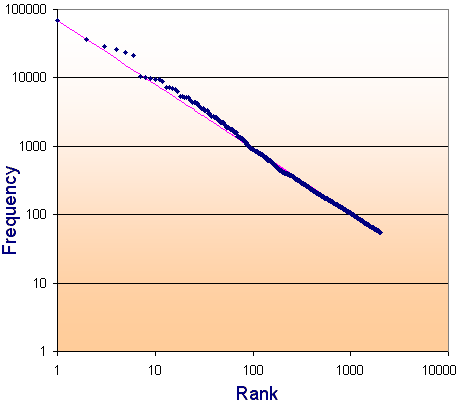
The blue dot on the top left represents the frequency of the word "the" (70,000 times) and rank 1. Each blue dot after that represents the rank order vs frequency of the word. This is based on the count of one million words in a large range of sources. You are seeing the first 2,000 words in rank order.
A log-log graph (where the log of the rank is the scale for the horizontal axis and the log of the frequency is the vertical axis) is used to show better detail in the extremities.
I added this topic in the semi-log and log-log graphs section of Interactive Mathematics, Application: Zipf Distributions.
I included an analysis of the most recent 500,000 page views in Interactive Mathematics, and the pattern is similar to what Nielsen obtained for his own site. The pattern breaks down for less-visited pages (the right-hand end of the data).
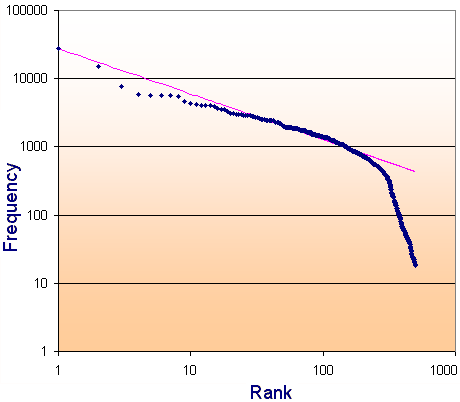
The same distribution is observed when examining incoming links to a site (Google is nearly always at the top).
Update: Useit.com has some earlier articles on this topic which throw more light on the issue:
Do Websites Have Increasing Returns?, a 1997 article where he introduces the concepts.
Traffic Log Patterns, which is a 2006 update.
See the 1 Comment below.
30 Jul 2007 at 6:59 am [Comment permalink]
[...] squareCircleZ » Zipf Distributions, log-log graphs and Site Statistics [...]